近日,江西理工大学计算智能实验室负责人李伟老师指导的学术论文《Reinforcement learning-based particle swarm optimization with neighborhood differential mutation strategy》在国际权威期刊《Swarm and Evolutionary Computation》上发表。该研究成果提出了一种名为NRLPSO的粒子群算法,能够有效求解单目标优化问题。

论文链接:https://doi.org/10.1016/j.swevo.2023.101274
期刊简介:《Swarm and Evolutionary Computation》是人工智能与智能计算领域重要学术期刊。该期刊主要报道自然启发式智能计算、跨学科领域的最新研究和发展成果,长期位于中科院计算机科学和工程技术等学科一区,也是该领域的Top期刊。
作者简介:李伟博士是我校计算智能实验室负责人,现为IEEE Computational Intelligence Society会员、中国计算机学会会员、中国仿真学会智能仿真优化与调度专业委员会副监事长、江西省计算机学会智能计算专委会副主任委员。主要从事智能计算、进化算法、进化深度学习及智能优化等理论与应用研究,在智能计算领域特别是基于智能优化算法方面取得了一系列研究成果。
论文摘要:粒子群优化(PSO)算法已成为解决各种工程优化问题最有效的方法之一。大多数现有的PSO变体经常使用固定算子,采用固定算子学习模式可能会限制每个粒子的智能水平,从而降低PSO在解决复杂适应度景观优化问题时的性能。为了解决单目标实参数数值优化问题,同时克服上述缺点,本文提出了一种基于强化学习的邻域差分变异策略粒子群优化(NRLPSO)。在NRLPSO中,设计了动态振荡惯性权重(DOW)策略,为粒子提供不同情况下的动态调整能力。为了解决探索和开发的算子选择难题,开发了一种基于强化学习的速度向量生成(VRL)策略。在每次迭代中,粒子选择基于强化学习的速度更新模型,VRL有助于彻底搜索问题空间。应用基于余弦相似度(VCS)的速度更新机制来控制速度学习模式以确定更有希望的解决方案。此外,为了缓解早熟收敛问题,采用邻域差分突变(NDM)的局部更新策略来增加算法的多样性。为了验证所提出算法的效率,实施了CEC2017和CEC2022测试套件,并对九种经典或最先进的PSO变体进行了全面测试。实验结果表明,NRLPSO在收敛速度和精度方面优于流行的PSO变体。
主要贡献:
1.提出了一种基于强化学习的速度矢量生成策略。在NRLPSO算法中,环境是粒子的搜索空间。粒子状态分为探索、利用、收敛和跳出,种群中的每个粒子都处于这些状态中的一种。动作的定义是从一种状态通过执行该动作实现到另一种状态的转换。
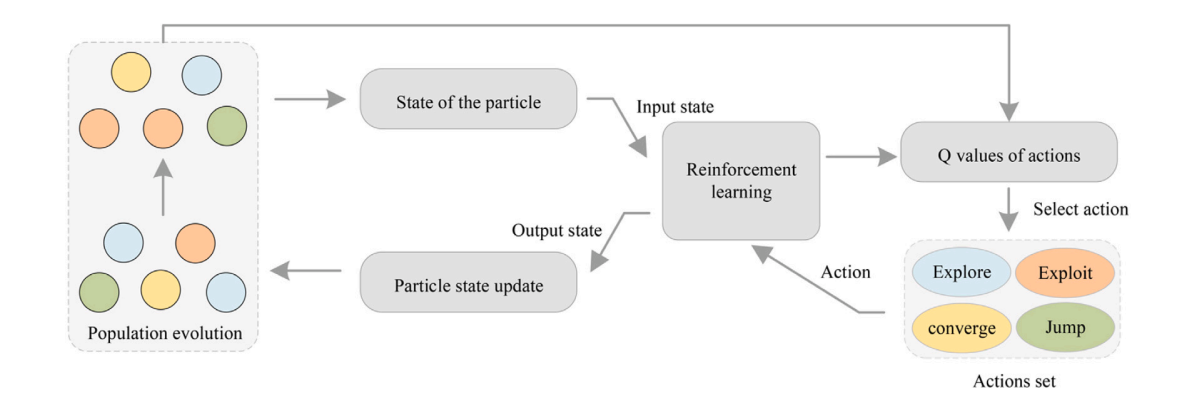
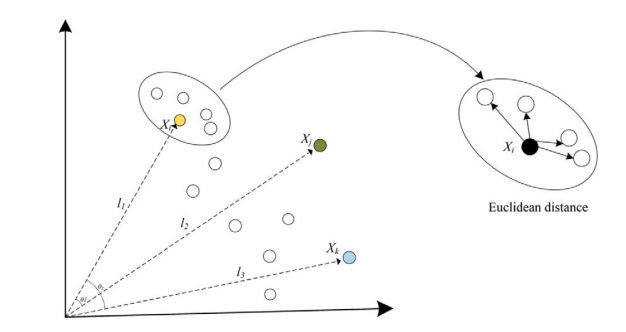
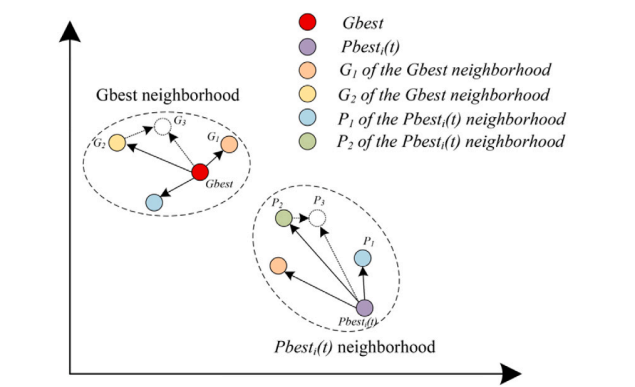
2.惯性权重作为粒子群优化算法的参数之一,可使粒子在各种情况下具有动态调整能力,以实现算法局部和全局搜索能力之间的平衡。基于种群的优化方法中,在搜索的早期阶段多样性更为重要,变化较大的惯性权重有利于种群充分搜索整个问题空间。在搜索的后期阶段,为了成功收敛到最佳解决方案,变化较小的惯性权重有利于对解决方案进行微调。范式的选择对引导粒子运动起着至关重要的作用,好的范式能更好地引导粒子运动,不好的范式会导致粒子早熟成为局部最优。然而,很少有学者关注两种范式之间的联系对粒子运动的影响。该成果利用余弦相似度分析了两种范式之间的相似度,设计了一种基于余弦相似度的速度更新机制用于粒子速度更新。
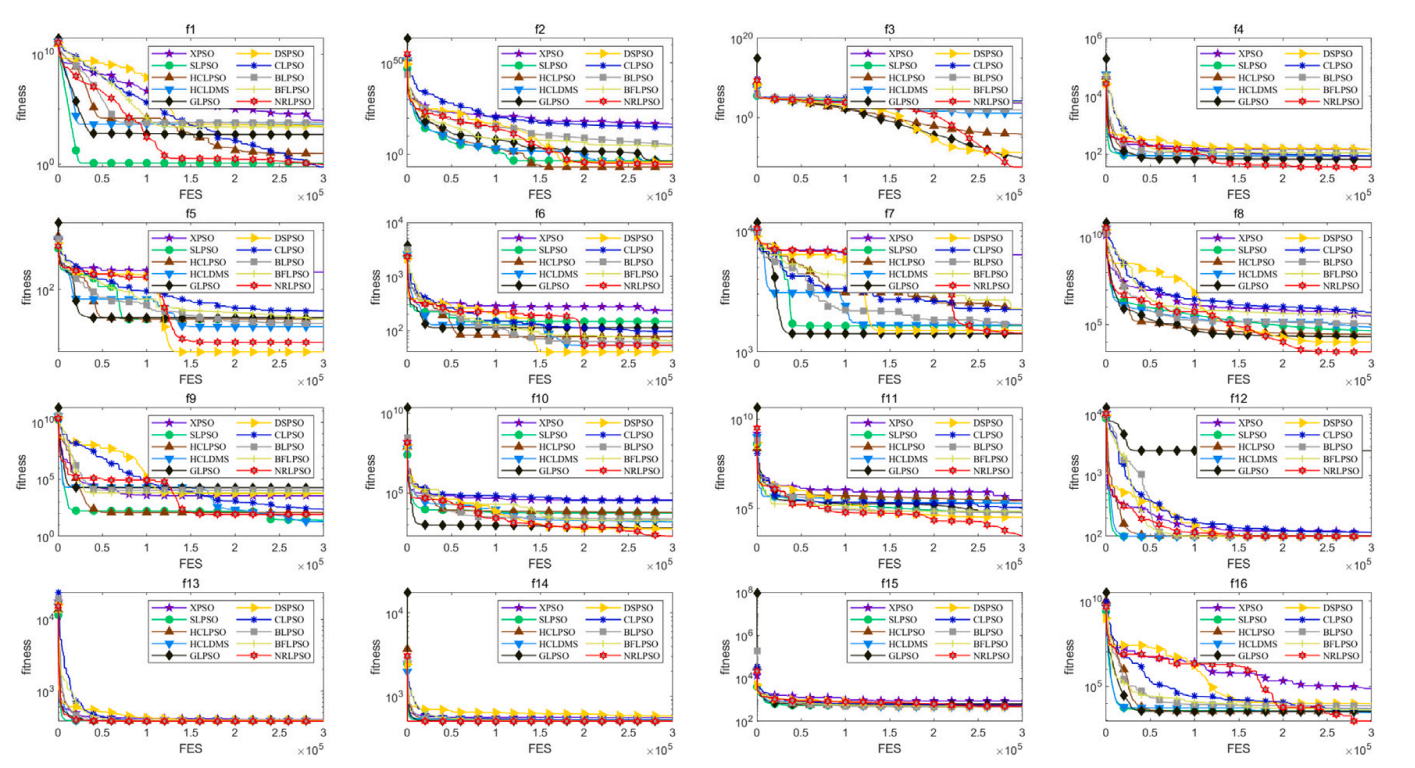
3.为了评估所提算法的性能,该成果选取CEC2017和CEC2022中景观特征差异较大的测试函数,分别从参数敏感性分析、策略有效性分析、收敛精度分析以及收敛性与稳定性分析等四个方面进行充分实验,并与SLPSO、CLPSO、XPSO、GLPSO、BLPSO、BFLPSO、HCLPSO、HCLDMS-PSO和DSPSO这些经典或先进的粒子群变体进行了比较。实验每个测试函数按照CEC标准独立运行51次,所选算法的终止条件为最大评估次数。
致谢:以上工作得到了国家自然科学基金、多维智能感知与控制江西省重点实验、江西省自然科学基金等项目的资助。
