近日,江西理工大学计算智能实验室负责人李伟老师指导的学术论文《An Information Entropy-Driven Evolutionary Algorithm Based on Reinforcement Learning for Many-Objective Optimization》在国际权威期刊《Expert Systems With Applications》上发表。该研究成果提出了一种名为RL-RVEA的多目标优化算法,能够有效解决多目标优化问题。

论文链接:https://doi.org/10.1016/j.eswa.2023.122164
期刊简介:《Expert Systems With Applications》是人工智能与智能计算领域重要学术期刊。该期刊主要报道自然启发式智能计算、跨学科领域的最新研究和发展成果,长期位于中科院计算机科学和工程技术等学科一区,也是该领域的Top期刊。
作者简介:李伟博士是我校计算智能实验室负责人,现为IEEE Computational Intelligence Society会员、中国计算机学会会员、中国仿真学会智能仿真优化与调度专业委员会副监事长、江西省计算机学会智能计算专委会副主任委员。主要从事智能计算、进化算法、进化深度学习及智能优化等理论与应用研究,在智能计算领域特别是基于智能优化算法方面取得了一系列研究成果。
论文摘要:多目标优化问题(MaOPs)具有挑战性,需要同时优化多个相互冲突的目标。近年来,基于分解的多目标进化算法能够有效平衡种群的收敛性和多样性。然而,这些算法在精确逼近不规则、具有复杂几何结构的Pareto前沿(PFs)时面临挑战。针对具有不规则Pareto前沿的多目标优化问题,本文提出了一种基于强化学习的信息熵驱动进化算法(RL-RVEA)。该算法利用强化学习来指导进化过程,通过与环境交互来学习PF的形状和特征,自适应地调整参考向量的分布以有效覆盖PFs结构。此外,设计了一种信息熵驱动的自适应标量化方法来反映非支配解的多样性,使得算法能够自适应地平衡多个竞争目标,在保持个体多样性的同时完成解的高效选择。为了验证所提出算法的有效性,RL-RVEA在DTLZ、MaF和WFG测试集以及四个真实世界的MaOPs上与七个最先进的算法进行了比较。实验结果表明,该算法为求解具有不规则PFs的MaOPs问题提供了一种新颖实用的粒子群优化方法。
主要贡献:
1.提出了一种基于信息熵驱动的自适应标量化环境选择方法,为下一代种群保留更多多样性的解。
2.引入了一种基于强化学习的自适应参考向量策略,该策略可用于与环境交互以学习如何调整参考向量。
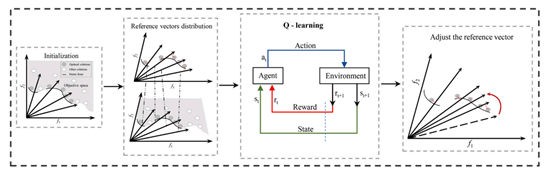
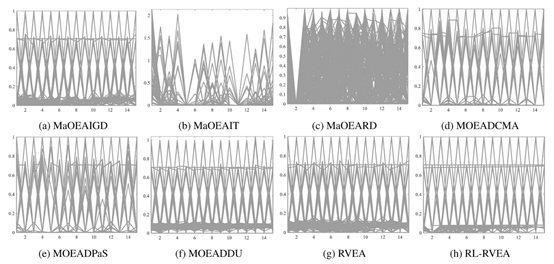
3.将RL-RVEA与几种最先进的MOEAs进行了比较。实验结果表明,RL-RVEA在处理具有不规则PFs的MaOPs时表现良好。
致谢:以上工作得到了国家自然科学基金、多维智能感知与控制江西省重点实验、江西省自然科学基金等项目的资助。
